Machine learning: if a picture is worth a thousand words





Automatic file editing, image classification, object identification in photos and videos, asset and product monitoring, and even emotion and action recognition based on Face Recognition. According to the Observatories of the Politecnico di Milano, these are the most promising applications of artificial intelligence that use machine learning to analyse data.
By Lorenzo Capitani | On PRINTlovers #88
Why do certain sites ask you to recognise abstruse letters, select traffic lights, pedestrian crossings, bicycles and buses, or click on “I am not a robot”? It is not only to verify that you are human beings and not computers with bad intentions (so-called bots) but also to train artificial intelligence. Captcha tests (that’s the name of those little quizzes, from “Caught you!”), based on the more classic Turing test to distinguish computers from humans, are needed not only for security but above all to teach machines to read and recognise specific objects within a picture. Science fiction from the Matrix? Absolutely not, as we shall see.
In 1997, researchers at AltaVista, to prevent bots from adding URLs to their search engine in a fraudulent way, had the idea of exploiting in reverse the features of the OCR programme of the Brother scanner they had in their office. If a text is garbled, overlaps with another, the characters change, or the background is not homogeneous, they thought, the machine can no longer interpret it, but a human can. This intuition was also exploited by the Carnegie Mellon University of Pittsburgh when it started the digitisation of its library, and had the idea of submitting the dubious words identified by OCR to the users in the form of Captcha: if a person succeeds in correctly identifying a known word, then she/he will also identify the unknown one, and when three people give the same answer, this can be filed by the system as correct. It worked so well that in September 2009, this technology was bought by Google.
Experience
Today, artificial intelligence and machine learning - i.e. the mechanism whereby systems learn and improve their performance and responsiveness based on the data they use - are almost everywhere. From Siri responding appropriately to questions, learning from what you ask her and how satisfactory her answer is, to the magic wand in Photoshop that recognises a subject and knows how to isolate it from the background (Filtro su colore di fondo.jpg), not just based on colour difference, but because it can recognise and distinguish individual elements. But artificial intelligence also comes into play when we interact with banks, shop online or use social media, read the news or choose a movie on Netflix, right up to the car that recognises road signs and lanes. Even outside the context we are interacting with at that moment - and in unexpected ways - machine learning mechanisms are constantly coming into play to make our experience efficient, easy and safe. Let’s think about images: Google’s free service for storing them, for instance, on the one hand gives us space to store our photos and on the other uses them to learn.
Faithful to the Faustian pact according to which ‘if you don’t pay, you are the product’, it is we who authorise, more or less spontaneously and unconsciously, the use of our information, which is not only what we share on social networks but, above all, all the rest of it: from email attachments to the documents we store in the Cloud, to the images from security cameras that pass through and are stored on the network. Beyond the aspects of privacy and profiling, which then take a back seat between capricious authorisations (Do you want the service? Give me access to the data!) or those granted lightly, artificial intelligence probes and learns from everything it is fed; the computational power and the goodness of the algorithm do the rest. In a sort of Moebius strip, the AI analyses data, processes them, learns, and provides data that it reuses to analyse, process, and so on. An example is the filters in certain apps, like FaceApp, that alter the appearance of our selfies. The photo goes to their servers, is stored with millions of others, processed according to the filters set and sent back to the app: just keeping the processed version or deleting it means teaching AI to do better. The same happens with the new neural filters in the 2021 version of Photoshop, which from this release always works closely with the Adobe cloud, to such an extent that ‘Save As’ proposes it as the default destination. The ‘smooth skin’ or ‘sky replacement’ filters are extremely realistic but the ones that really impress with their accuracy are the ‘make-up transfer’, whereby make-up is applied from an uploaded target photo, and the ‘intelligent portrait’, which alters the expression of a face in a range from happiness to anger. And it is no coincidence that these filters ask the user, after the effect is applied, whether they are satisfied or not.
Learning from your mistakes
But how does a computer learn? To put it briefly, it does so by classifying, processing and learning from feedback on its work, according to more or less supervised algorithms. The logic that exploits the continuous correction of results based on a given model, even with human intervention, is the most widely used today. As Oracle explains, “just as a child learns to identify fruits by memorising them from a picture book, so the algorithm is trained starting off from a data set that is already labelled and classified.” In contrast, unsupervised algorithms “use an independent approach, in which the computer learns to identify processes and patterns on its own without any guidance: in this case, it is as if a child learns to identify fruits by looking at colours and patterns, without memorising the names with the help of a teacher: it will look for similarities between images and divide them into groups, assigning each group the new label.” This is how Apple’s Face ID works: it reads a face, makes a map of it and saves it. Then, every time you want to unlock the device, it compares the face at that moment with the saved map. The recognition rating does the rest: if it looks like the model, the phone unlocks, and anything that differs is saved to refine the map. So, for example, the phone unlocks whether you are wearing glasses or not. It is evident that the two methods end up improving each other. Once a new label is identified, it, in turn, becomes a model. The process is summarised by the formula put forward in 2017 by Robin Bordol, CEO of Crowdflower: AI = TD (Training Data) + ML (Machine Learning) + HITL (Human In The Loop).
Image Recognition
Today, the AI landscape is taking off: the various machine learning engines for data analysis operate mainly based on neural networks for processing photos, videos and texts that can recognise shapes, colours and even follow moving objects. According to the Observatories of the Politecnico di Milano, the most promising applications are the automatic editing of files, the classification of images, the identification of objects within photos and videos, and the monitoring of assets and products and even recognition of emotions and actions based on Face Recognition. First of all, a large number of features are extracted from the image, which is composed of pixels. Without going into too much detail, once each image has been converted into thousands of features, you can begin to train a model. In the case of photos representing, for example, undamaged products and faulty products, we can train the machine to recognise one of the two categories. The more images we use for each category, the better a model can be trained: once it has learned, it can recognise an unknown image. For example, let’s take the image (Apple.jpg). If at the first processing it doesn’t recognise the Apple logo and mistakes it for the bitten apple silhouette (we tested it, and it doesn’t happen), after it has been trained, it will recognise it correctly.
Google Vision AI
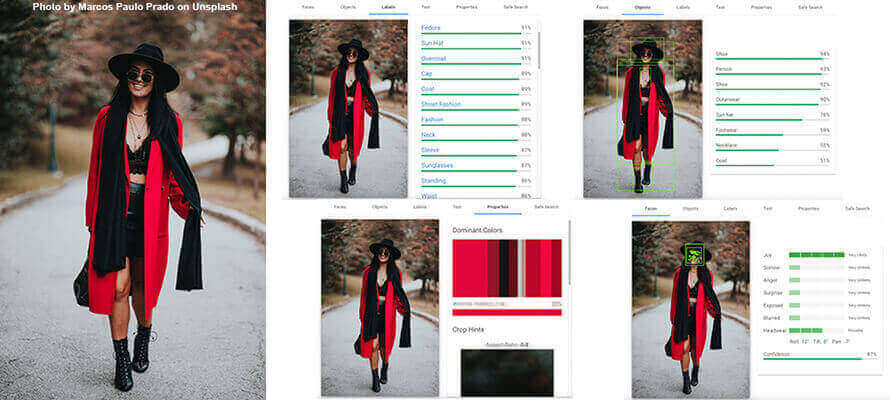
Let’s carry out an experiment. At https://cloud.google.com/vision, Google provides a simulator of its Vision AI. In the picture, it recognises in a few seconds that there is a person, specifically a woman, and that she is wearing a hat (it even recognises that it is a fedora), a coat, and necklaces. It assigns a recognition rate to each of the details it detects, and so the algorithm tells us that there are 94% shoes, 87% sunglasses. But it doesn’t stop there; it associates labels (bag, trees, trench coat, fashion), classifies facial expressions (joy), verifies how safe the image is for sensitive content (sex, violence, racial content), creates a colour map with values in RGB and their coverage in percentages, and excludes background colours to avoid false positives. Finally, it isolates individual parts and maps their coordinates. This little experiment alone reveals the potential of the instrument. Feed it all the images of your products and teach it to recognise the details that interest you, correct it when it makes mistakes, and you’ll have a wealth of data to use. How? Let’s take a fashion e-commerce site: using this data, I could build a gallery based on colours, distinguish worn photos from still-life, push logoed garments into specific markets or towards particular users who appreciate these details, aggregate by product type or gender and so on, without anyone having spent time classifying the images and, just as importantly, without anyone pre-determining what to look for. And this is also the case for exploring new or unconsidered areas of business. The basic Google system works across a broad spectrum and has the advantage of offering all the strength of the Mountain View giant’s ecosystem and experience, as well as its ability to compute and integrate with its other Cloud services. Vision AI can work silently on the images stored on its servers, materialise the extracted data and make it available. The decision is then made on which approach to take, whether supervised or unsupervised, and even as far as to intervene on the algorithm. Once the data has been extracted, you can proceed by inclusion or exclusion of particular results (e.g. I’m not going to show a bikini in certain markets’ e-commerce sites) or on the best match, i.e. how close an image is to a given example. A tangible example is the Reverse Image Search tool on Google’s home page. Just feed it a picture, and it will instantly find all the similar ones, up to finding the same one in other size variants. I can automatically base typical suggestions such as matches and You May Also Like on tools like these.
Other approaches
An equally powerful alternative is Amazon Rekognition, which can be activated directly in AWS, probably Amazon’s most popular cloud computing and hosting service. It can identify objects, people, text, scenarios and activities in photos and videos and recognise content in text as well. The uses here are numerous and depend on the business: they range from facial recognition (e.g. celebrities, authorised persons, employees) of objects and scenes to the identification of forbidden content to carry out moderation or human verification, from text recognition to the identification of one’s own products among the photos published on social media or present on the shelves of a shop for market research. For example, Nike’s experiment of filming all the participants in the 2019 Tokyo Marathon on a wire to identify and classify the brands and models of shoes used by participants is interesting. Amazon Rekognition is directly integrated with Amazon Augmented AI (Amazon A2I) to easily implement human review for inappropriate image detection. Amazon A2I provides an integrated human review workflow for image moderation, enabling easy review and validation of Amazon Rekognition’s predictions. Among the independent platforms, the main one is undoubtedly Clarifai, which adopts a supervisable approach with lots of workflow to manage learning according to specific user needs; it adopts compelling solutions for image, video and text recognition in particular contexts such as food. Not only can it identify individual products or ingredients but also preparations and dishes. For travel, on the other hand, it can also extrapolate the location, services offered or characteristics of locations, hotels and residences from a photo. The strength of Clarifai’s algorithms lies in their ability to work in circumscribed areas with known and specific characteristics, thus increasing the precision of the results. One example is the automatic recognition of garments and accessories or the classification of textures and patterns for fashion. The approach, in this case, is not only to recognise text and make it editable but also to classify it according to its content to moderate unwanted content, search for keywords and concepts, or carry out web reputation analyses.
Information architecture
Going from having little data, perhaps painstakingly extracted by hand, to this enormous mass can be disorienting. Before asking yourself what to classify, you should ask yourself why to do so, perhaps starting from a specific need. The great thing about these solutions is that they do not follow linear processes: they are like networks, and they are scalable. You can move in any direction and easily change the depth of analysis just by changing the algorithm and reprocessing the files. For example, I could start with just tagging for classification and then take advantage of identifying objects to which to link actions. This is what happens, for instance, with the Ikea app, where in the photos of the environment, the objects have been associated with hot spots that link to the product details with the relative colour variants and the possibility of adding them directly to the shopping cart. As you can see, these tools, although strongly machine-based, still require human intervention to refine the result. It is a paradigm shift: I leave the most onerous, time-consuming and low-value work to the machine and concentrate on training the algorithm.
A good approach that can be followed is to proceed in steps. First, let’s take the tags of the photo (shutterstock.jpg) taken from Shutterstock: it has more than 200 generic keywords associated with it, ranging from the apt “woman” to the incomprehensible “quadrant” - though “lily” and even “flower” are completely missing - and there’s also “wear” and “vintage”. Then, if my context is fashion, I skim off the errors, add tags based on specific semantics: that “wear” will become the “stonewashed” of jeans, the weave of the band will be identified as “diamond-shaped”; this is because AI examines visual signs (vectors, shapes and colours) and compares them with reference models, and it is precisely on taxonomies, classifications and localisations that we need to work.
360-degree AI
If these automatisms save repetitive actions on images, think what can be done with a video, where moving images require almost frame-by-frame intervention. In this case, Sensei, Adobe’s AI engine, is truly state-of-the-art. We mentioned above the artificial intelligence applied to Photoshop tools, but that’s just the tip of the iceberg. What Adobe proposes is a genuine ecosystem, made up of ‘small’ functionalities, such as the neural filters in Photoshop, present in the new releases of the applications that simplify the work of graphic designers and creatives; but above all, it is made up of powerful processing engines integrated in the Experience Cloud and Marketing Cloud suites, the family of products for digital business, which allows end-to-end coverage of the entire production and distribution process, reducing bottlenecks. Let’s think about a library of images of products stored on Adobe DAM: Sensei can automatically identify the objects contained, isolate them, crop them, dynamically obtaining the cutting coordinates photo by photo, and then create other renditions ready for distribution or prepared for subsequent reuse. The advantage becomes exponential when we think of videos. Let’s consider an editorial video for an e-commerce site. Adobe covers the stages from production - with the editing and montage of the film, the recognition of details (the products), the assignment of specific tags for the CEO and SEM of the site, the application of dynamic areas that even follow moving subjects to which events can be associated - to distribution. By that we mean the construction of the web page that hosts it and the CMS to deliver the media responsively according to the device from which you are browsing regardless of the size and shape of the user’s screen (Sensei’s AI comes to detect the point of focus and to operate the cuts accordingly, ensuring that the chosen subject is always sharp and in the middle of the scene). The work carries on up to the collection and analysis of all the classic analytics data.
Today, access to data has become much more straightforward, awareness of its value is growing, leading to a transformation of business processes. The vital thing is not to let yourself be frightened by its potentially immense vastness: in that way, you can learn how to navigate in the sea of information without finding yourself swept away or completely washed up.
08/10/2021


